Hyperparameters Overview
Configure and optimize model behavior through hyperparameter tuning
Overview
Hyperparameters are external configurations set before training that define how a model learns. Unlike model weights, these are not learned directly from data, so finding the right balance is critical for performance and generalization.
Rather than relying on a single fixed setup, tuning systematically evaluates different parameter combinations using search strategies and cross-validation to identify configurations that generalize well to unseen data.
This section provides an overview of hyperparameter tuning, the available tuning strategies, and general guidance on selecting appropriate settings.
When to Use Hyperparameter Tuning
Hyperparameter tuning is commonly used when:
- Model performance is a priority
- Default parameter values are unlikely to be optimal
- The dataset has non-trivial size or complexity
Tuning may be skipped for quick experiments, baseline models, or when training time needs to be minimized.
Tuning Methods
Grid Search
Evaluates all possible combinations of the specified parameter values.
Characteristics:
- Exhaustive and deterministic
- Best suited for small parameter spaces
- Can become computationally expensive as parameters increase
Random Search
Evaluates a fixed number of randomly sampled parameter combinations.
Characteristics:
- Efficient for large parameter spaces
- Often finds strong configurations with fewer evaluations
- Controlled by the number of sampled iterations
Bayesian Optimization
Bayesian optimization selects new parameter combinations based on the results of previous evaluations.
Characteristics:
- Efficient for expensive training runs
- Focuses the search on promising regions of the parameter space
- Requires fewer iterations to converge on good results
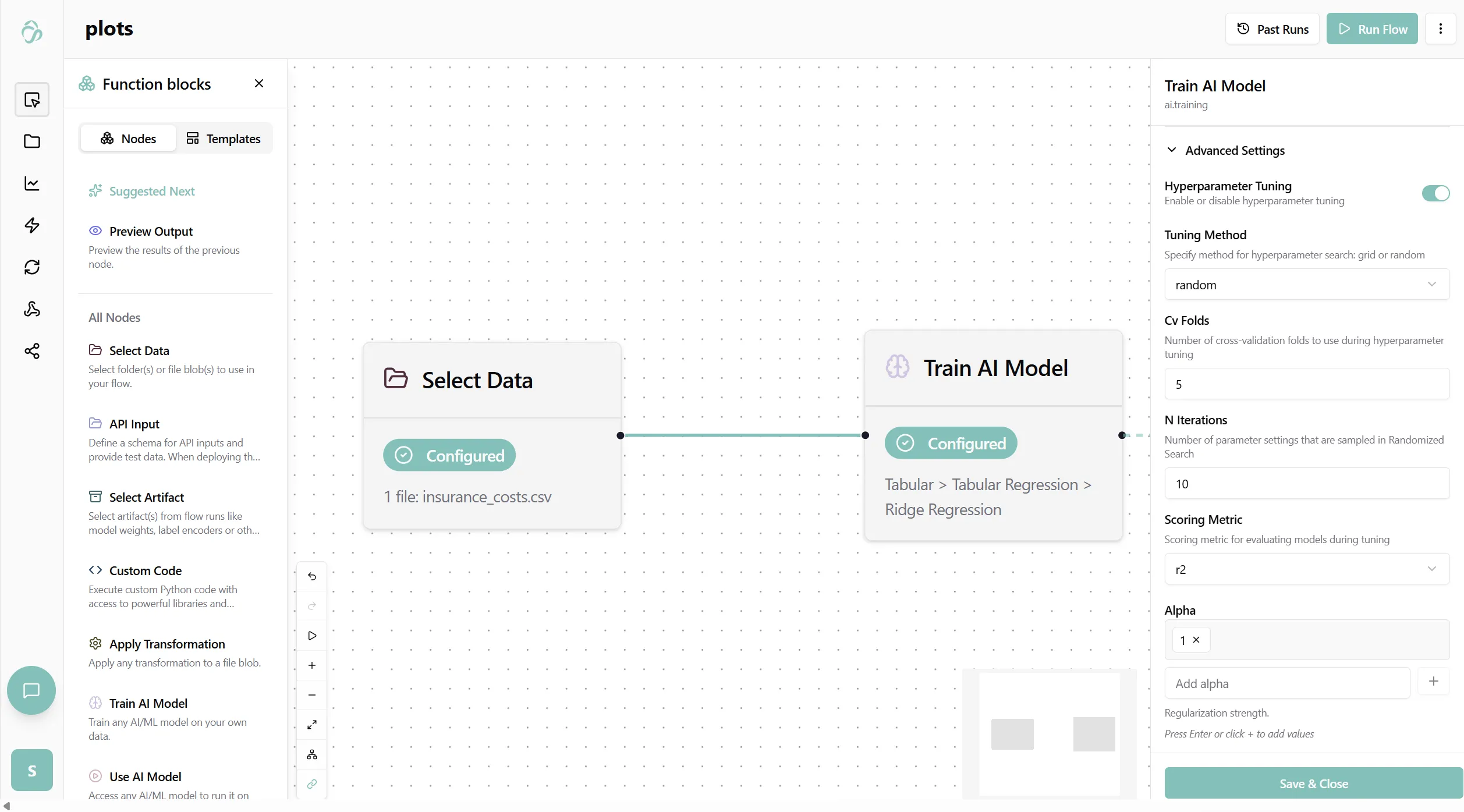
Options for Hyperparameter Tuning
Hyperparameter tuning is controlled through a small set of configuration options that define whether tuning is enabled, how the search is performed, and how model performance is evaluated.
-
use_hyperparam_tuning- Enables or disables hyperparameter tuning. When set tofalse, the model is trained using a single fixed configuration. -
tuning_method- Defines the search strategy used to explore the hyperparameter space. -
cv_folds- Specifies the number of cross-validation folds used during tuning. Configurations are evaluated across all folds and averaged to reduce variance and provide more reliable results. -
n_trials- Controls how many parameter configurations are evaluated. This is required for strategies that explore a subset of the search space, such as random search and Bayesian optimization. -
scoring_metric- Determines the metric used to measure model performance. The configuration with the highest score is selected as the final choice.
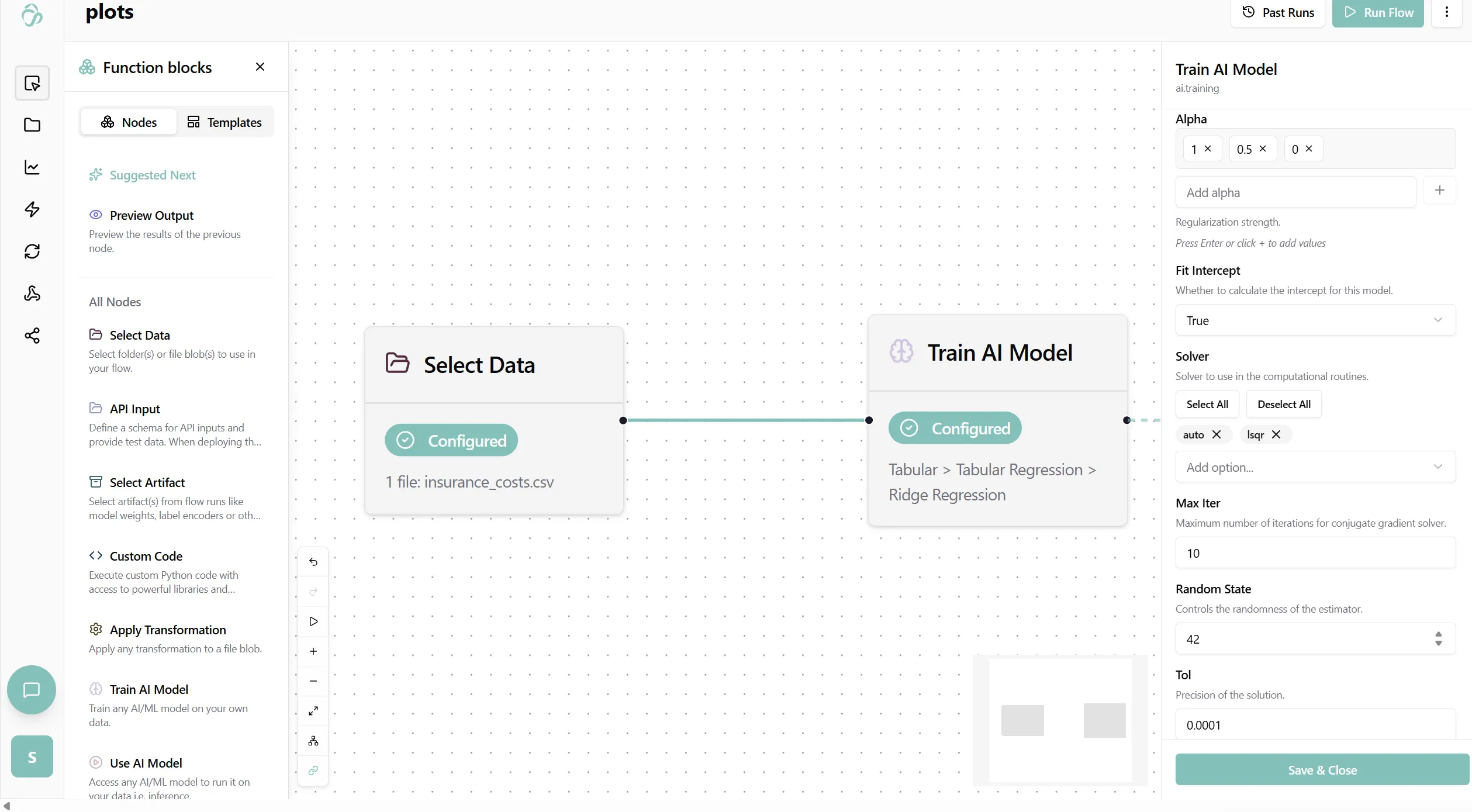
When tuning is enabled, individual parameters transition from fixed settings to search spaces, allowing to input multiple candidate values:
Hyperparameter Selection Guidelines
General recommendations:
- Start Small: Begin with default values and enable tuning selectively. Focus on high-impact parameters related to regularization and optimization, rather than tuning all parameters at once.
- Balance Reliability and Speed: Increasing
cv_foldsimproves the reliability of evaluation but also increases training time. - Prioritize the Right Metric: Select a
scoring_metricthat aligns with the modeling objective. For imbalanced datasets, metrics such as F1 score or ROC AUC may provide a more meaningful evaluation than accuracy. - Manage Complexity: Increase search complexity or the number of tuned parameters only if initial results are unsatisfactory. Small, targeted search spaces often yield the best balance between performance and efficiency.
Training Outcome
Once tuning completes:
- The best parameter configuration is selcted
- A final model is trained using the entire training dataset (all folds combined) using these parameters
- The resulting model is ready for evaluation, inference, or deployment
Notes
- Computational overhead: Tuning is resource-intensive and extend total training time.
- Reproducibility: Fixed random seeds ensure consistent results across runs.
- Data Dependency: The effectiveness of tuning depends on the quality and representativeness of the dataset.